Slurm作业调度系统
SLURM (Simple Linux Utility for Resource Management)是一种可扩展的工作负载管理器,已被全世界的国家超级计算机中心广泛采用。 它是免费且开源的,根据GPL通用公共许可证发行。
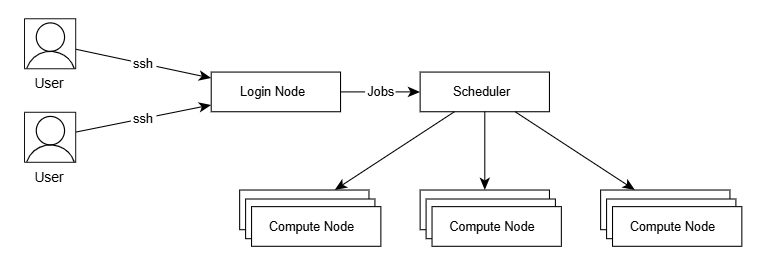
连接集群后,进入的是登录/数据传输节点,不能直接进行计算,需要通过作业调度系统,将作业提交到计算节点上执行。
提交作业可以通过 SCOW可视化平台,也可以通过SHELL登录后,通过命令提交。
警告:
1.请勿在登录/数据传输节点进行计算操作,登录/数据传输节点做了资源限制,直接在登录/数据传输节点进行计算不仅速度慢,还有可能导致登录/数据传输节点卡顿。
2.集群只有数据传输节点联网,联网下载数据、本地文件上传下载请登录数据传输节点进行。
Slurm 概览
Slurm |
功能 |
sinfo |
集群状态 |
squeue |
排队作业状态 |
sbatch |
作业提交 |
scontrol |
查看和修改作业参数 |
sacct |
已完成作业报告 |
scancel |
删除作业 |
sinfo 查看集群状态
Slurm |
功能 |
sinfo -N |
查看节点级信息 |
sinfo -N --states=idle |
查看可用节点信息 |
sinfo --partition=cpu |
查看队列信息 |
sinfo --help |
查看所有选项 |
节点状态包括:drain(节点故障),alloc(节点在用),idle(节点可用),down(节点下线),mix(节点部分占用,但仍有剩余资源)。
查看总体资源信息:
![]()

squeue 查看作业信息
Slurm |
功能 |
squeue -j jobid |
查看作业信息 |
squeue -l |
查看细节信息 |
squeue -n HOST |
查看特定节点作业信息 |
squeue |
查看USER_LIST的作业 |
squeue --state=R |
查看特定状态的作业 |
squeue --help |
查看所有的选项 |
作业状态包括R(正在运行),PD(正在排队),CG(即将完成),CD(已完成)。
默认情况下,squeue只会展示在排队或在运行的作业。
sbatch 作业提交
准备作业脚本然后通过sbatch提交是 Slurm 的最常见用法。
$ sbatch job.slurm
Slurm 具有丰富的参数集,以下最常用的。
Slurm |
含义 |
-n [count] |
总进程数 |
--ntasks-per-node=[count] |
每台节点上的进程数 |
-p [partition] |
作业队列 |
--job-name=[name] |
作业名 |
--output=[file_name] |
标准输出文件 |
--error=[file_name] |
标准错误文件 |
--time=[dd-hh:mm:ss] |
作业最大运行时长 |
--exclusive |
独占节点 |
--mail-type=[type] |
通知类型,可选 all, fail, end,分别对应全通知、故障通知、结束通知 |
--mail-user=[mail_address] |
通知邮箱 |
--nodelist=[nodes] |
偏好的作业节点 |
--exclude=[nodes] |
避免的作业节点 |
--depend=[state:job_id] |
作业依赖 |
--array=[array_spec] |
序列作业 |
以下是一个名为cpu.slurm的作业脚本,该脚本向cpu队列申请1个节点40核,并在作业完成时通知。在此作业中执行的命令是/bin/hostname。
#!/bin/bash
#SBATCH --job-name=test
#SBATCH --partition=C056M0256G
#SBATCH -n 40 #每个节点申请的核数
#SBATCH -N 1 #执行任务申请的节点数
#SBATCH -q cpu_qos #C056M0256G分区当前使用的qos策略
#SBATCH --output=%j.out
#SBATCH --error=%j.err
/bin/hostname
用以下方式提交作业:
sbatch cpu.slurm
squeue可用于检查作业状态。用户可以在作业执行期间通过SSH登录到计算节点。输出将实时更新到文件[jobid].out和[jobid] .err。
下面展示一个更复杂的作业要求,其中将启动80个核,每台主机40核。
#!/bin/bash
#SBATCH --job-name=test
#SBATCH --partition=C096M1024G
#SBATCH -n 80
#SBATCH --ntasks-per-node=40
#SBATCH -q fat_qos #C096M1024G分区当前使用的qos策略
#SBATCH --output=%j.out
#SBATCH --error=%j.err
以下作业是请求4张GPU卡,其中1个CPU进程管理1张GPU卡。
#!/bin/bash
#SBATCH --job-name=GPU_Test
#SBATCH --partition=GPU80G
#SBATCH -n 4
#SBATCH --ntasks-per-node=4
#SBATCH --gres=gpu:4
#SBATCH --output=%j.out
#SBATCH --error=%j.err
srun 和 salloc 交互式作业
srun可以启动交互式作业。该操作将阻塞,直到完成或终止。例如,在计算主机上运行hostname。
srun -N 1 -n 4 -p C056M0256G hostname
compute001
启动远程主机bash终端:
srun -p cpu -n 4 --pty /bin/bash
或者,可以通过salloc请求资源,然后在获取节点后登录到计算节点:
salloc -N 1 -n 4 -p C056M0256G
ssh compute001
scontrol: 查看和修改作业参数
Slurm |
功能 |
scontrol show job JOB_ID |
查看排队或正在运行的作业的信息 |
scontrol hold JOB_ID |
暂停JOB_ID |
scontrol release JOB_ID |
恢复JOB_ID |
scontrol update dependency=JOB_ID |
添加作业依赖性 ,以便仅在JOB_ID完成后才开始作业 |
scontrol show job JOB_ID |
查看排队或正在运行的作业的信息 |
scontrol hold JOB_ID |
暂停JOB_ID |
scontrol hold 命令可使排队中尚未运行的作业暂停被分配运行,被挂起的作业将不被执行。scontrol release 命令可取消挂起。
sacct 查看作业记录
Slurm |
功能 |
sacct -l |
查看详细的帐户作业信息 |
sacct --states=R |
查看具有特定状态的作业的帐号作业信息 |
sacct -S YYYY-MM-DD |
在指定时间后选择处于任意状态的作业 |
sacct --format=“LAYOUT” |
使用给定的LAYOUT自定义sacct输出 |
sacct --help |
查看所有选项 |
sacct -l |
查看详细的帐户作业信息 |
默认情况下,sacct显示过去 24小时 的帐号作业信息。
查看更多的信息:
Sacct --format=jobid,jobname,account,partition,ntasks,alloccpus,elapsed,state,exitcode -j 3224
查看平均作业内存消耗和最大内存消耗:
sacct --format="JobId,AveRSS,MaxRSS" -P -j xxx
Slurm环境变量
Slurm |
功能 |
$SLURM_JOB_ID |
作业ID |
$SLURM_JOB_NAME |
作业名 |
$SLURM_JOB_PARTITION |
队列的名称 |
$SLURM_NTASKS |
进程总数 |
$SLURM_NTASKS_PER_NODE |
每个节点请求的任务数 |
$SLURM_JOB_NUM_NODES |
节点数 |
$SLURM_JOB_NODELIST |
节点列表 |
$SLURM_LOCALID |
作业中流程的节点本地任务ID |
$SLURM_ARRAY_TASK_ID |
作业序列中的任务ID |
$SLURM_SUBMIT_DIR |
工作目录 |
$SLURM_SUBMIT_HOST |
提交作业的主机名 |